
First of all, a brief explanation of what iterative development is: to build software by dividing the work into phases or iterations, performing in each of them what would be the complete software development cycle, that is, analyze, design, implement, test and deliver, all with its corresponding planning.
Each iteration or turn of the screw may have a different duration from the others, based on the objective that is outlined and the scope of the work to be developed, but (except for the first one) they always start from the previous one and end with a tangible that can be validated.
The main advantages of the iterative model is to be able to practice a divide and conquer approach, since activities are broken down into iteration cycles, making their execution easier, while maximizing internal validations (testing) and external validations (partial deliveries to the customer). This method evolved into what today are agile development methodologies such as Scrum.
Analyze, design, implement, test and deliver
Although Scrum has many good things, leaving it to chance (or to the team’s doing) that sprints are self-contained, with tangible results, is a serious problem that in most projects surfaces in the form of an inability to close features or stabilize systems. In a manner of speaking, the objective of the Iterative development is that each iteration or development cycle (of whatever duration) ends and can be a product, intermediate if we want to see it that way, but a product: each iteration is like an episode of Black Mirror. However, when we work in Scrum without the objective and obligation to tangibly deliver a final product in each sprint, what we have are episodes of The Walking Dead, where we have to wait for the next chapter to see what happens.

Of course, iterative development can be implemented in Scrum, they are neither opposite nor exclusive: the difference is in how the features are built, not in how the tasks and assignments derived from that build are controlled. The ideal from my point of view is to fit iterations within the sprints.
Although it may seem counterintuitive, we are returning to older ways of working (not organizational methodologies). There is a tendency to follow a cascade model, so defenestrated in the 2000s due to its proven ineffectiveness in incorporating changes and adjustments quickly: we now tend to organize the work among different profiles (Front / Back) for which it is necessary to do the work in sequence, analyzing and designing everything to be able to distribute the tasks, generate JIRAs and assign them on the board hoping that at the end of the tunnel we will find ourselves. And this is complicated. The absence of a software construction strategy can lead to what is called a Wagile, Waterscrum o Scrummerfall.
On the contrary, the iterative construction model, which I insist can perfectly fit in Scrum, allows you to start working in small pieces, simplifying the need to analyze or design in detail an entire development, whether it is a functional module or just a screen. The example I always use is a list screen with its filters, sorting, row styles, pagination and the typical export to Excel: we can start analyzing the tasks needed to build everything, separate them for two people to implement (Front & Back) and wait for them to finish implementing it praying that they have not forgotten anything and that they understand each other. Then, maybe after two weeks, at the end of the sprint, it’s all done and working. Moreover, we could show that page to the client in a demo, and he/she would give the OK to it. But this never happens, it’s like capturing a unicorn.
Iterate over the object until it becomes the target
If we apply some decomposition guidelines to that task that would take two weeks and break it down into three iterations, even with a time overrun that leads to three weeks of work, we may be able to secure a better result:
- Iteration 1. Let’s just make the list, something easy: no styles, no filters, no sorting or anything. One page and a simple mapper. Risks minimized, result ensured in the first iteration which, by simple
can be very fast. It is functional, can be tested and shared with the QA department and the customer. - Iteration 2. With an OK to our first iteration, let’s go for the second one: let’s tackle filters and search, and maybe pagination. It is about modifying what we already have in place and have taught. Again, at the end of the iteration, you can partially test it and show it to the customer: here for sure.
that asks for one or two more filters or some adjustment, but we already have it. - Iteration 3. We incorporated the client’s settings and the bugs found and tried to close the functionality, including the export to Excel. We have the client’s OK to the columns, formats and filters, so exporting to Excel something that we have already built and validated is easy. We maximize the success and productivity of our work by relying on previously verified work.
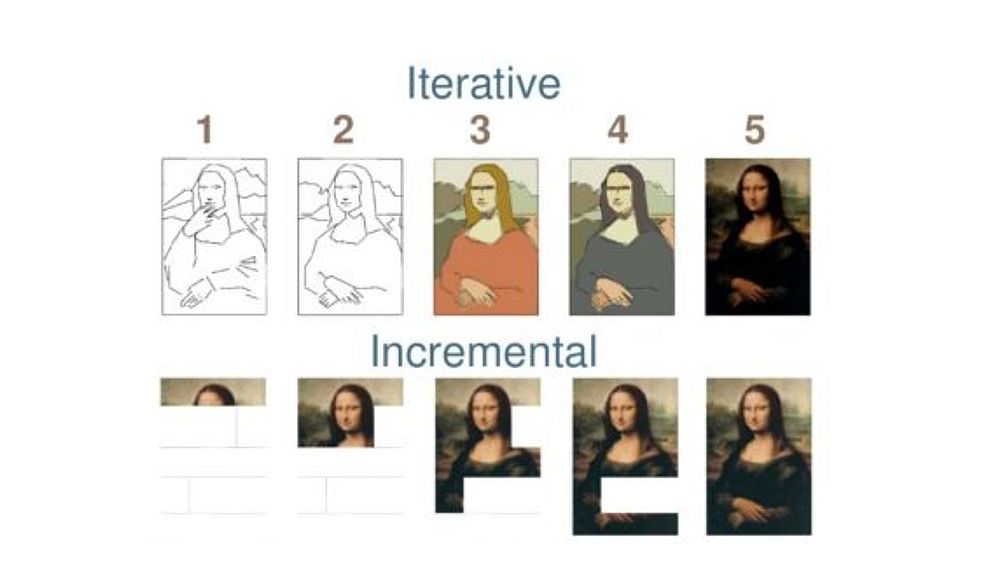
Iterating is art, in the sense that it reproduces the natural creative process of any plastic discipline, for example painting or sculpture. The natural way to unveil and validate the work we do, often closer to a painting in the Prado Museum than to a construction plan, is to iterate on the object until it becomes the objective. However, what we do when we are simply working in incremental mode (which would be to divide tasks in Scrum and implement them one by one) has the disadvantage of not being able to see the work until it is completely finished.
I insist that Scrum is a very good way to organize work and tasks, but it is very important to be able to define the way in which we build incrementally, providing that iteration that will help us greatly to have control and mastery of the projects.




